If you have been hanging around lately, you may have heard that AI is becoming huge and that new AI startups are being born every day. In fact, you don't need to be a visionary to realize that AI is already changing the way we live, work, and interact with each other.
Almost twenty years ago, AI was the subject of my graduation thesis, so I have a good grasp of concepts like machine learning, AI algorithms, neural networks, etc. Having said that, things have evolved quickly since then and I've been asking myself many questions recently. A very important one is whether AI can help humanity evolve or involve itself, but that's another story. I feel like I am already going a bit off topic for a blog discussing commerce for developers. Hence, I'll focus on the technical aspects, starting from the core concepts.
My goal is to show that there is nothing magical about AI. Computers haven't suddenly evolved into intelligent beings. They are just machines fed by algorithms and models that are trained with vast amounts of data. It is only through learning the workings of those models that we can gain a better sense of what's happening around us as well as make better predictions about what's to come in ecommerce and other fields.
From equal to similar
It is very easy for computers to determine if two things are equal. Bits are either one or zero. Numbers can be equal, less than, or greater than each other. In reality, the world is often made of shades, variations, and intents that are difficult for machines to decode or generate.
In order for machines to act more like humans, they must understand similarity. The problem is that it is much more complex for an algorithm to tell if an object is similar to another than it is for a human. In fact, understanding similarity is one of the tasks in which humans have always excelled over machines. As of now, at least.
A traditional search engine, for example, will only understand that two keywords are synonymous if they have been tagged as such. Without a human's input, an algorithm cannot determine if the words "trousers" and "pants" are similar, for instance. Consequently, a search results page will always be empty unless either the exact keyword is included in the search query, or the query includes a synonym tagged by a human.
Artificial intelligence enhances the ability of machines to determine similarity. This reduces the gap between humans and machines in solving problems that are less deterministic. With higher computational power, machines are even surpassing humans. But how are they able to do that? To answer this questions, we need to take a step back and talk about vectors, a data format that makes it easier to measure the similarity between objects.
Measuring similarity with vectors
Any object can be described by a number of features. As an example, if we want to describe two objects based on their size, we can assign a value to each object's "size" feature and we will say that they are similar if their values are not too far apart. However, two objects may have a similar size, but be very different in another aspect.
Suppose you want to classify a hamster, a toad, and a cat based on their size and beauty. Each feature is given a score between 0 and 10. Below is an example of a possible classification:
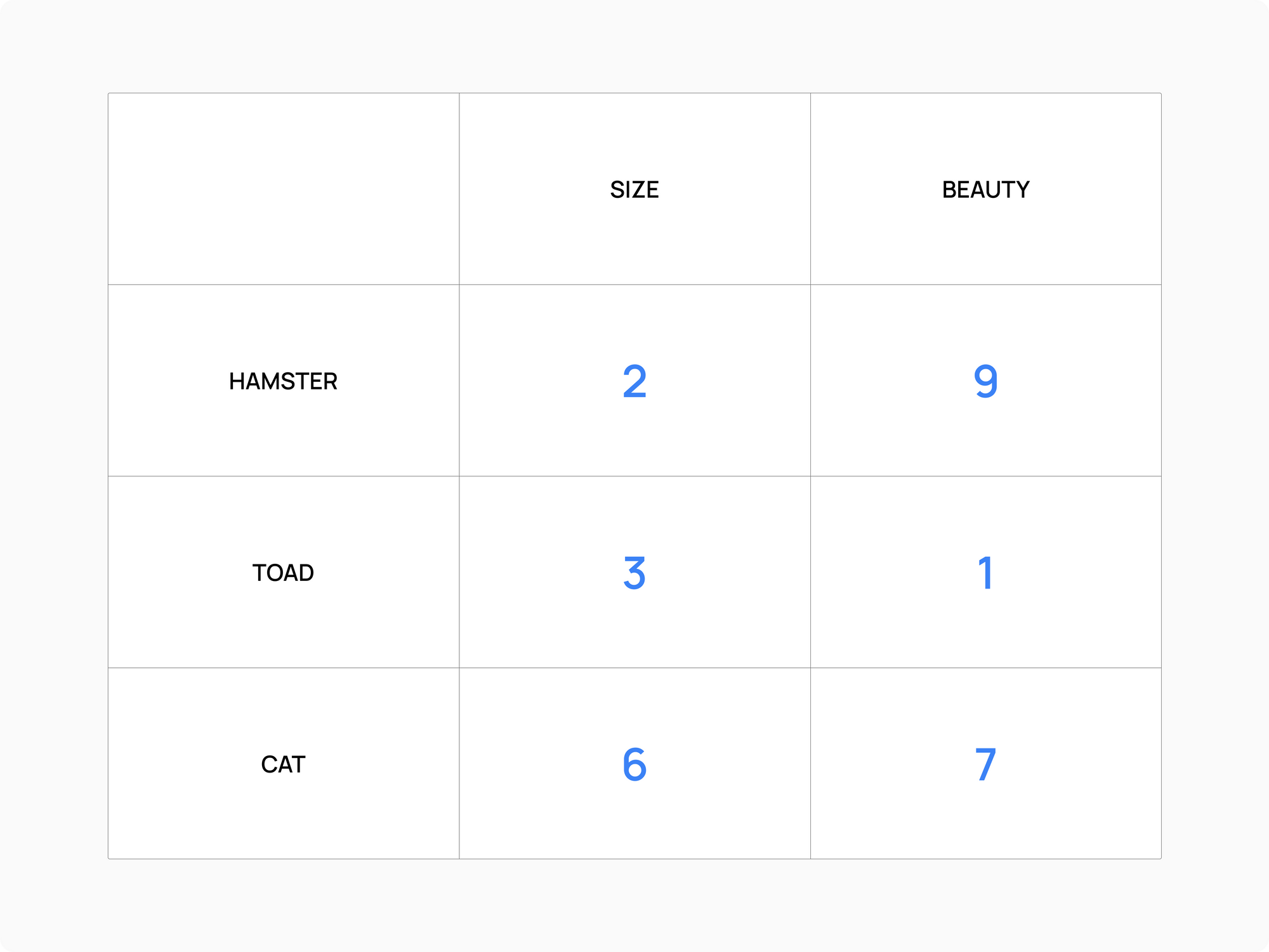
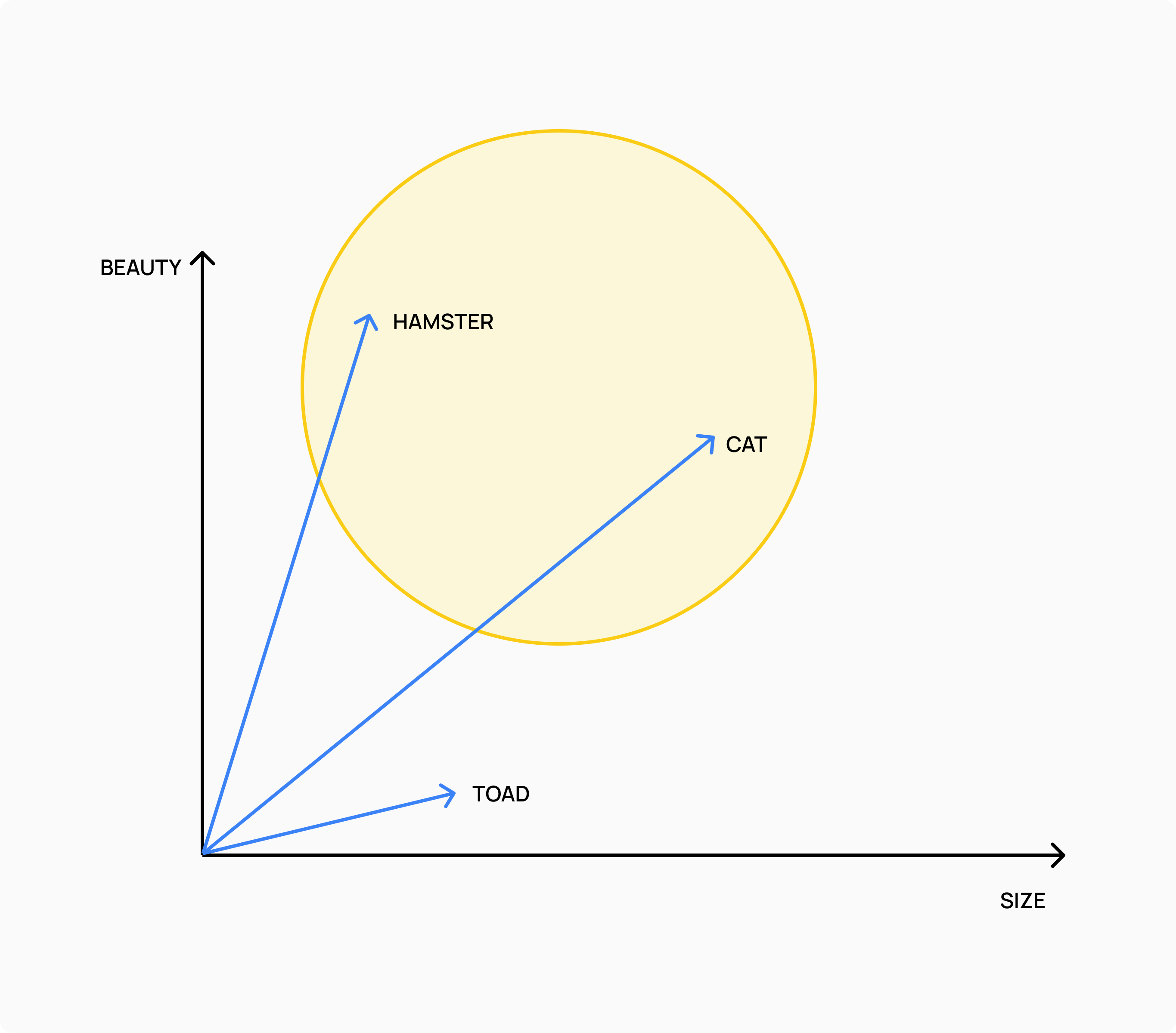
Using to this model, each of the three animals is represented by an array of two features, or a vector in a bidimensional plane. A hamster and a toad have similar sizes, but a hamster is much more like a cat in terms of beauty (sorry toads). In fact, the distance between the three vectors shows that a hamster is more like a cat than a toad.
In a more sophisticated model, three features could be represented by vectors in three dimensions. Likewise, multidimensional models can be represented in multidimensional spaces. Regardless of the vector dimensions, the core behavior remains the same.
Introducing vector databases
AI-powered applications often rely on vector databases. As their name suggests, vector databases store vectors and allow for similarity search using proximity algorithms. When you provide a vector (the query), they will return similar vectors, i.e. those in a certain distance from the query.
Any type of document, be it text, images, videos, or audio can be vectorized and stored into a vector database. This allows AI applications to manipulate any type of unstructured data through similarity search based on vector distance. The process of transforming data into vectors is carried out by machine learning models, which are AI models trained to recognize and extract certain types of patterns or features.
Like us, AI models learn from examples. Training those models involves using large data sets that have been annotated by humans with predicted results. After training, the model can recognize the same patterns across objects within the same domain. Generally, the more sophisticated the model, the greater the vector dimensions and data set required for training. In most vector databases, you can search millions of vectors in a matter of milliseconds.
E-commerce and AI
Ecommerce can greatly benefit from similarity search and generative AI, based on the same vector and machine learning principles described above. You can use AI to generate product descriptions, automate search, make recommendations, personalize shopping experiences, or engage in conversational commerce.
All these use cases have one thing in common: they all manipulate content. While AI is capable of giving users immersive and innovative ways to discover products, it might not have the same impact when it comes to showing a price, the availability of a product, or managing a shopping cart.
I believe AI-generated prices and promotions are already being used in some industries (such as the airline industry), but AI cannot generate stock that doesn't exist in a warehouse or manipulate credit card transactions. You might be able to use AI to optimize the risk assessment of a transaction, but not the transaction itself.
Transactional commerce resonates better with the "equal" paradigm than the "similar" paradigm. This demonstrates yet again how content and commerce are very different. Keeping these two domains separate will let you experiment with new cool technologies and embrace any winner that emerges from this AI revolution.