As software architects, we always try to ensure that data is normalized and that we never create a second copy of the same piece of content. Many CMSs are designed to follow this principle: content editors create content and publish it logically by changing a publishing status, which determines the visibility (and caching rules) for that content.
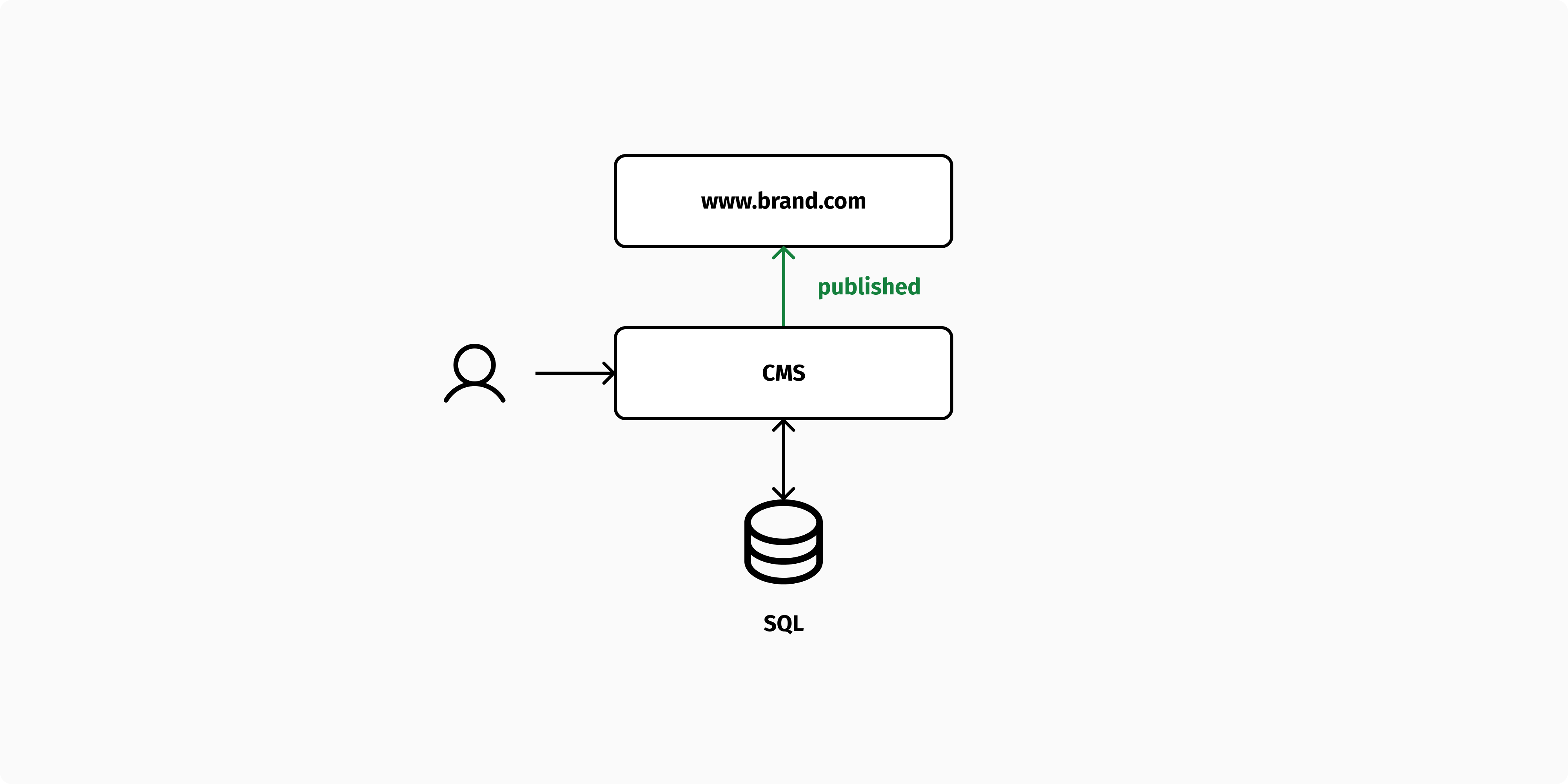
While this principle makes perfect sense, it does have some downsides since content management and delivery have very different requirements. The content management process is performed by a relatively small number of users who have a need for a flexible data model and a user-friendly editing interface. Instead, content delivery is a read-only service that a larger number of users access through a website or application.
A headless CMS typically provides a flexible schema that enables you to define any content model through its content management API. In order to provide this level of flexibility, they make use of generic data structures for "models" and "fields.” Once published, the content can be accessed via a content delivery API built on top of the same underlying database.
Even if cached aggressively, this data structure can become a performance bottleneck when delivering content, especially for large datasets such as a product catalog classified using a deep taxonomy tree. This is particularly true when the catalog needs to be searched and filtered on the client side, lowering its cacheability.
In such cases, it might be worth splitting the architecture into two stacks: one for content management and one for content delivery. The content management stack can be flexible and does not have to offer production-ready performances. In contrast, the content delivery stack is allowed to be more rigid, but highly optimized for performance and availability. As an example, it could use a NO-SQL database or a search engine, as described in one of my previous articles.
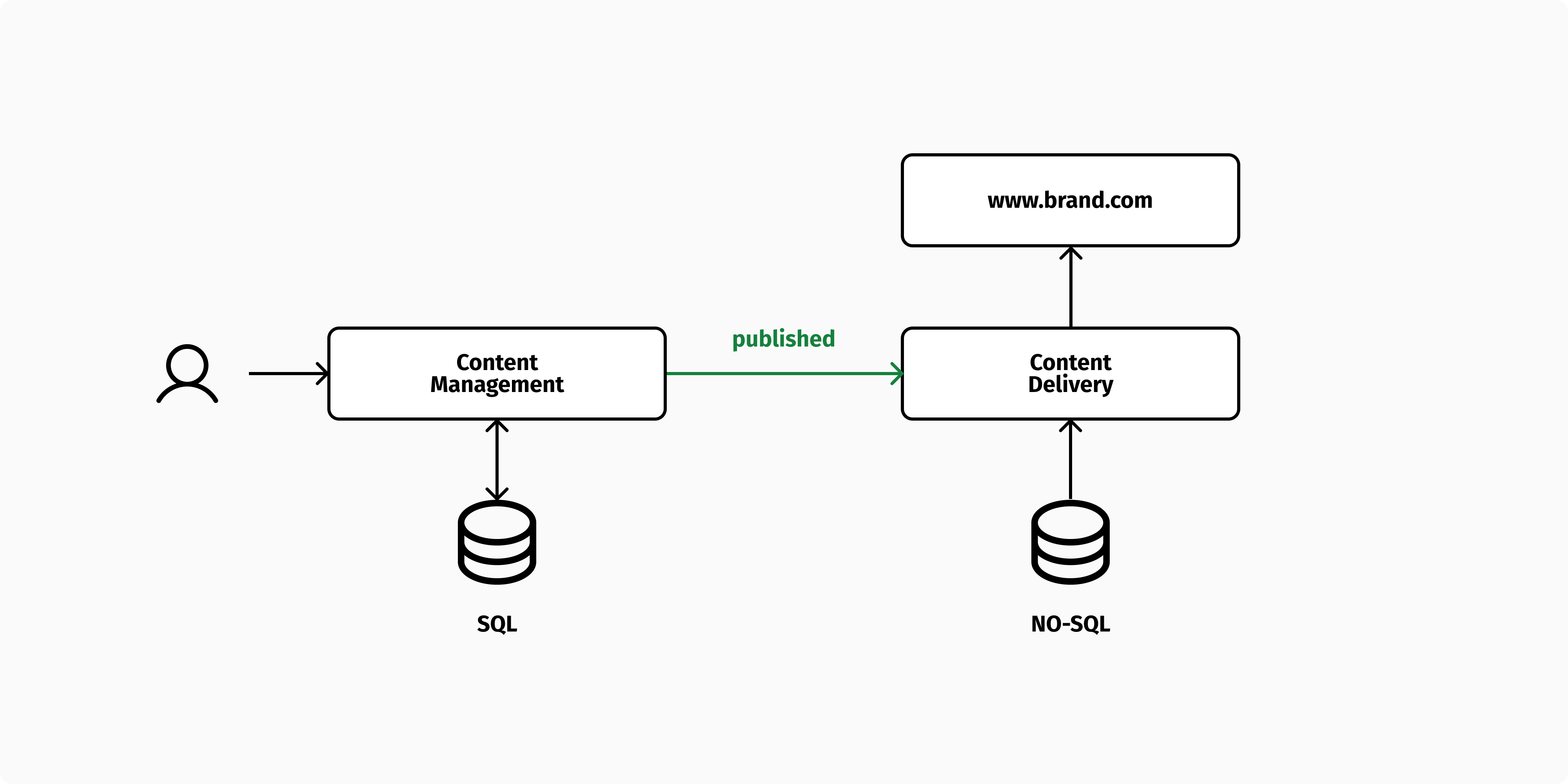
In the most extreme case, the content delivery stack can contain no database at all, but just a statically generated website delivered over a CDN (aka Jamstack). Regardless of how the content delivery stack is built, this pattern makes the publishing process more “physical”, as one piece of content is published when it is copied (and transformed) from the content management stack to the content delivery stack. As a result, previewing and approving content becomes easier, as you can publish a version of your data to a stack that is similar to production, which serves as a preview environment and possibly a staging area for new features.
While copying data from one system to another violates the principles of data normalization in some way, it fully embraces the principles of composability. The data is managed and delivered by two separate components that are highly optimized for different types of users. Each stack is constructed using best-in-class components that meet the needs of the specific use case.
Segregating content editing and publishing is not new, as a testament to the fact that good software design principles never go out of style. Martin Fowler from Thoughtworks first presented it over a decade ago. A couple of years later, his colleague Sunit Parek successfully applied this principle to manage the product catalog of a global manufacturer. Martin and Sunit described their solution as the "Two-Stack CMS" architecture and made it publicly available as a deck—I hope they don't mind if I borrow their term.